
CSRF
CSRF(Cross Site Request Forgery),跨站请求伪造,
它利用用户已登录的身份,在用户毫不知情的情况下,以用户的名义完成非法操作。
攻击者盗用了你的身份,以你的名义发送恶意请求,对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的一个操作,比如以你的名义发送邮件、发消息,盗取你的账号,添加系统管理员,甚至于购买商品、虚拟货币转账等。 如下:其中Web A为存在CSRF漏洞的网站,Web B为攻击者构建的恶意网站,User 为Web A网站的合法用户。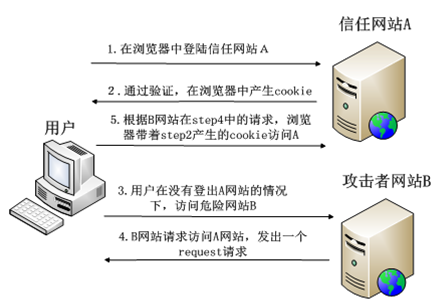
攻击过程:
1、 用户打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
2、 在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;
3、 用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;
4、 网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
5、 浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。
防御手段:
1、 验证 HTTP Referer 字段
根据 HTTP 协议,在 HTTP 头中有一个字段叫 Referer,它记录了该 HTTP 请求的来源地址。在通常情况下,访问一个安全受限页面的请求来自于同一个网站,比如需要访问 http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory,用户必须先登陆 bank.example,然后通过点击页面上的按钮来触发转账事件。这时,该转帐请求的 Referer 值就会是转账按钮所在的页面的 URL,通常是以 bank.example 域名开头的地址。而如果黑客要对银行网站实施 CSRF 攻击,他只能在他自己的网站构造请求,当用户通过黑客的网站发送请求到银行时,该请求的 Referer 是指向黑客自己的网站。因此,要防御 CSRF 攻击,银行网站只需要对于每一个转账请求验证其 Referer 值,如果是以 bank.example 开头的域名,则说明该请求是来自银行网站自己的请求,是合法的。如果 Referer 是其他网站的话,则有可能是黑客的 CSRF 攻击,拒绝该请求。
存在的问题:
1、部分浏览器存在漏洞,可以篡改 Referer 值,绕过验证
2、存在信息安全,隐私泄露问题,Referer 值 运行为空,无法验证
2、 在请求地址参数中添加 token 并验证
CSRF 攻击之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于 cookie 中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的 cookie 来通过安全验证。要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。
对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。 而对于 POST 请求来说,要在 form 的最后加上 <input type=”hidden” name=”csrftoken” value=”tokenvalue”/>,这样就把 token 以参数的形式加入请求了
存在的问题:
难以保证 token 本身的安全, 黑客可以在目标网站(尤其是一些论坛网站)上面发布自己个人网站的地址,黑客的网站也同样可以通过 Referer 来得到这个 token 值以发动 CSRF 攻击。这也是一些用户喜欢手动关闭浏览器 Referer 功能的原因。
3、 在 HTTP 头中添加 token 并验证
这种方法也是使用 token 并进行验证,和上一种方法不同的是,这里并不是把 token 以参数的形式置于 HTTP 请求参数之中,而是把它放到 HTTP 头中自定义的属性里。这样解决了上种方法在请求中加入 token 的不便,同时,通过 这种 ajax 请求的地址不会被记录到浏览器的地址栏,也不用担心 token 会透过 Referer 泄露到其他网站中去。
然而这种方法的局限性非常大,这种请求通常用于 Ajax 方法中对于页面局部的异步刷新,并非所有的请求都适合用这个类来发起,而且通过该类请求得到的页面不能被浏览器所记录下,从而进行前进,后退,刷新,收藏等操作,给用户带来不便。
XSS
XSS(Cross Site Scripting),跨站脚本攻击
XSS是一种代码注入攻击。攻击者通过在目标网站上注入恶意脚本,使之在用户的浏览器上运行。利用这些恶意脚本,攻击者可获取用户的敏感信息如 Cookie、SessionID 等,进而危害数据安全。
1、 反射型 XSS
反射性xss一般指攻击者通过特定的方式来诱惑受害者去访问一个包含恶意代码的URL。当受害者点击恶意链接url的时候,恶意代码会直接在受害者的主机上的浏览器执行。
反射型XSS的攻击步骤如下:
- 攻击者在url后面的参数中加入恶意攻击代码。
- 当用户打开带有恶意代码的URL的时候,网站服务端将恶意代码从URL中取出,拼接在html中并且返回给浏览器端。
- 用户浏览器接收到响应后执行解析,其中的恶意代码也会被执行到。
- 攻击者通过恶意代码来窃取到用户数据并发送到攻击者的网站。攻击者会获取到比如cookie等信息,然后使用该信息来冒充合法用户
的行为,调用目标网站接口执行攻击等操作。
2、 存储型 XSS
存储型 XSS主要是将恶意代码上传或存储到服务器中,下次只要受害者浏览包含此恶意代码的页面就会执行恶意代码。
存储型XSS的攻击步骤如下:
- 攻击者将恶意代码提交到目标网站数据库中。
- 用户打开目标网站时,网站服务器将恶意代码从数据库中取出,然后拼接到html中返回给浏览器中。
- 用户浏览器接收到响应后解析执行,那么其中的恶意代码也会被执行。
- 那么恶意代码执行后,就能获取到用户数据,比如上面的cookie等信息,那么把该cookie发送到攻击者网站中,那么攻击者拿到该
cookie然后会冒充该用户的行为,调用目标网站接口等违法操作。
3、DOM-based型 XSS
DOM型XSS的攻击步骤如下:
- 攻击者构造出特殊的URL、在其中可能包含恶意代码。
- 用户打开带有恶意代码的URL。
- 用户浏览器收到响应后解析执行。前端使用js取出url中的恶意代码并执行。
- 执行时,恶意代码窃取用户数据并发送到攻击者的网站中,那么攻击者网站拿到这些数据去冒充用户的行为操作。调用目标网站接口执行攻击者一些操作。
防御手段:
1、服务器端设置 cookie 为 http-only
在服务器端设置cookie的时候设置 http-only, 这样就可以防止用户通过JS获取cookie。对cookie的读写或发送一般有如下字段进行设置:
http-only: 只允许http或https请求读取cookie、JS代码是无法读取cookie的(document.cookie会显示http-only的cookie项被自动过滤掉)。发送请求时自动发送cookie.
secure-only: 只允许https请求读取,发送请求时自动发送cookie。
host-only: 只允许主机域名与domain设置完成一致的网站才能访问该cookie。
2、对 html, html 属性, URL, CSS 进行编码转义,不应该直接输出到页面
3、开启CSP网页安全策略
CSP(Content Security Policy),网页安全策略,是一种由开发者定义的安全性政策申明,通过CSP所约束的责任指定可信的内容来源,通过 Content-Security-Policy 网页的开发者可以控制整个页面中 外部资源 的加载和执行。
比如可以控制哪些 域名下的静态资源可以被页面加载,哪些不能被加载。这样就可以很大程度的防范了 来自 跨站(域名不同) 的脚本攻击。
如:1
2
3
4
5<meta http-equiv="Content-Security-Policy" content="
default-src http: https: *.xxx.com 'self' 'unsafe-inline' ;
style-src 'self' 'unsafe-inline' *.yyy.com;
script-src 'self' 'unsafe-inline' 'unsafe-eval' ;
">
默认设置(default-src):信任 http ,https协议资源,信任当前域名资源,信任符合.xxx.com的域名资源
CSS设置(style-src):信任当前域名资源,允许内嵌的CSS资源,信任来自.yyy.com下的CSS资源。
JS设置(script-src):信任当前域名资源,允许内嵌的JS执行,允许将字符串当作代码执行
4、浏览器开启X-XSS-Protection
目前该属性被所有的主流浏览器默认开启XSS保护。该参数是设置在响应头中目的是用来防范XSS攻击的。它有如下几种配置(默认为1):
0:禁用XSS保护。
1:启用XSS保护。
1;mode=block; 启用xss保护,并且在检查到XSS攻击是,停止渲染页面。
DoS/DDsS
DoS(Denial of Service),拒绝服务攻击, 目的就是让一个公开网站无法访问.
DDoS(Distributed Denial of Service), 分布式拒绝服务攻击,是 DoS 的升级版.
就是利用大量合法的分布式服务器对目标发送请求,从而导致正常合法用户无法获得服务。通俗点讲就是利用网络节点资源如:IDC服务器、个人PC、手机、智能设备、打印机、摄像头等对目标发起大量攻击请求,从而导致服务器拥塞而无法对外提供正常服务.
针对常见的cc攻击的防御手段:
1、备份网站
防范 DDOS 的第一步,就是你要有一个备份网站,或者最低限度有一个临时主页。生产服务器万一下线了,可以立刻切换到备份网站,不至于毫无办法。
备份网站不一定是全功能的,如果能做到全静态浏览,就能满足需求。最低限度应该可以显示公告,告诉用户,网站出了问题,正在全力抢修。
这种临时主页建议放到 Github Pages 或者 Netlify,它们的带宽大,可以应对攻击,而且都支持绑定域名,还能从源码自动构建。
2、HTTP 请求拦截
HTTP 请求的特征一般有两种:IP 地址和 User Agent 字段。比如,恶意请求都是从某个 IP 段发出的,那么把这个 IP 段封掉就行了。或者,它们的 User Agent 字段有特征(包含某个特定的词语),那就把带有这个词语的请求拦截。
可以从三个层次来拦截:
(1)专用硬件
Web 服务器的前面可以架设硬件防火墙,专门过滤请求。这种效果最好,但是价格也最贵。
(2)本机防火墙
操作系统都带有软件防火墙,Linux 服务器一般使用 iptables。比如,拦截 IP 地址1.2.3.4的请求,可以执行下面的命令。1
$ iptables -A INPUT -s 1.2.3.4 -j DROP
(3)Web 服务器
Web 服务器也可以过滤请求。拦截 IP 地址1.2.3.4,nginx 的写法如下1
2
3location / {
deny 1.2.3.4;
}
Apache 的写法是在.htaccess文件里面,加上下面一段1
2
3
4<RequireAll>
Require all granted
Require not ip 1.2.3.4
</RequireAll>
如果想要更精确的控制(比如自动识别并拦截那些频繁请求的 IP 地址),就要用到 WAF。
Web 服务器的拦截非常消耗性能,尤其是 Apache。稍微大一点的攻击,这种方法就没用了。
3、 带宽扩容
上面说的HTTP 拦截有一个前提,就是请求必须有特征。但是,真正的 DDOS 攻击是没有特征的,它的请求看上去跟正常请求一样,而且来自不同的 IP 地址,所以没法拦截。这就是为什么 DDOS 特别难防的原因。要想防范这类攻击,那就只有想办法扩容,把这些请求都消化掉。如:每个主机保 5G 流量以下的攻击,那就一口气买了5个。网站架设在其中一个主机上面,但是不暴露给用户,其他主机都是镜像,用来面对用户,DNS 会把访问量均匀分配到这四台镜像服务器。一旦出现攻击,这种架构就可以防住 20G 的流量,如果有更大的攻击,那就买更多的临时主机,不断扩容镜像。
4、CDN
CDN 指的是网站的静态内容分发到多个服务器,用户就近访问,提高速度。因此,CDN 也是带宽扩容的一种方法,可以用来防御 DDOS 攻击。
网站内容存放在源服务器,CDN 上面是内容的缓存。用户只允许访问 CDN,如果内容不在 CDN 上,CDN 再向源服务器发出请求。这样的话,只要 CDN 够大,就可以抵御很大的攻击。不过,这种方法有一个前提,网站的大部分内容必须可以静态缓存。对于动态内容为主的网站(比如论坛),就要想别的办法,尽量减少用户对动态数据的请求。
上面提到的镜像服务器扩容,本质就是自己搭建一个微型 CDN。各大云服务商提供的高防 IP,背后也是这样做的:网站域名指向高防 IP,它提供一个缓冲层,清洗流量,并对源服务器的内容进行缓存。
这里有一个关键点,一旦上了 CDN,千万不要泄露源服务器的 IP 地址,否则攻击者可以绕过 CDN 直接攻击源服务器,前面的努力都白费。
cloudflare 是一个免费 CDN 服务,并提供防火墙,高度推荐。

