什么是RDD
RDD(resilient distributed dataset) 弹性分布式数据集,RDD表示一个不可变的、可分区的、支持并行计算的元素集合(类似于 Scala 中的不可变集合),RDD可以通过 HDFS、Scala集合、RDD转换、外部的数据集(支持InputFormat)获取,
并且 Spark 将 RDD 存储在内存中,可以非常高效的重复利用或者在某些计算节点故障时自动数据恢复。
RDD依赖 - lineage(血统)
在对RDD应用转换操作时,产生的新 RDD 对旧 RDD 会有一种依赖关系称为 Lineage(血统).
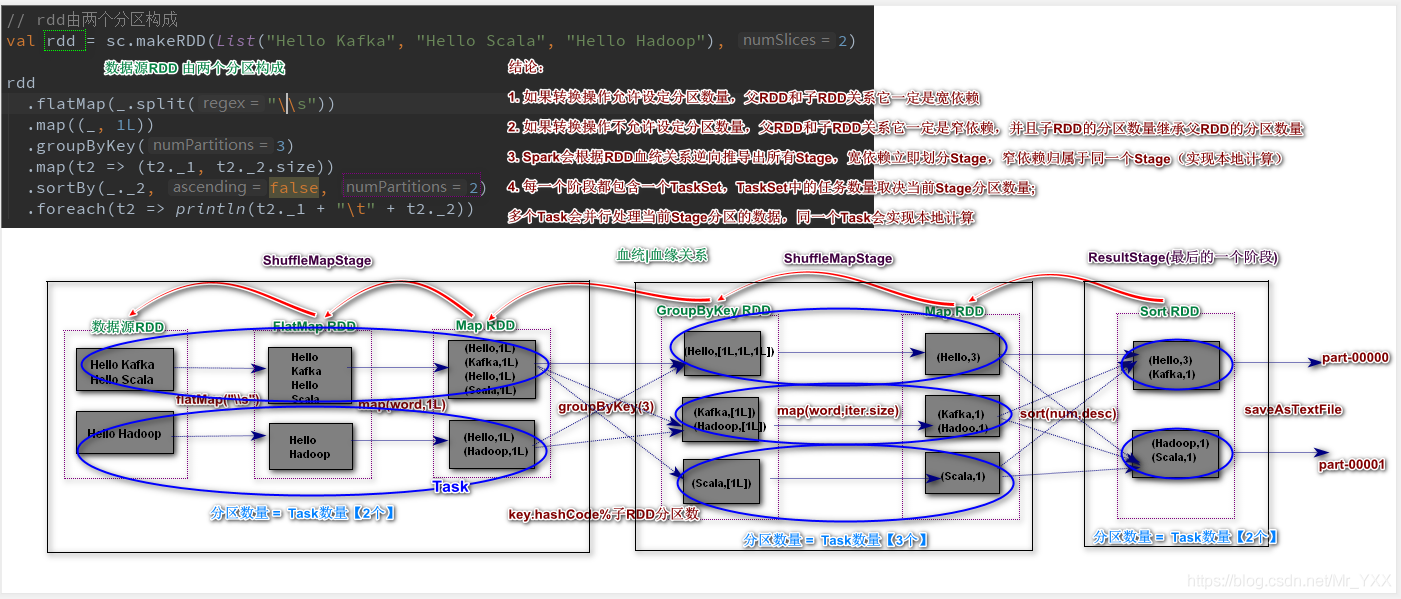
Spark应用在计算时会根据 Lineage 逆向推导出所有Stage(阶段),每一个 Stage 的分区数量决定了任务的并行度,一个 Stage 实现任务的本地计算(大数据计算时网络传输时比较耗时的.
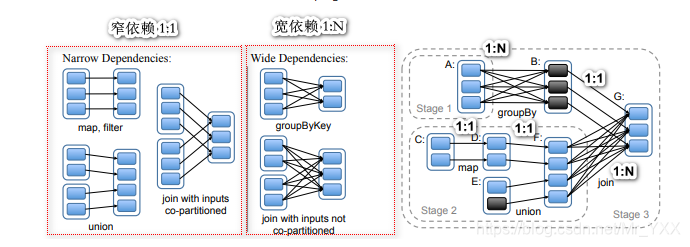
RDD 两种 Lineage 关系,宽窄依赖,v它们和Stage划分有极为紧密关系
窄依赖 (Narrow Dependency): 父RDD的一个分区对应一个子RDD的分区(1:1)或者多个父RDD的分区对应一个子RDD的分区(N:1).
宽依赖 (Wide Dependency): 父RDD的一个分区对应多个子RDD的分区(1:N).